
nvidia显卡算力对比,nvidia gpu算力
本文摘要: 大家好,感谢邀请,今天来为大家分享一下nvidia显卡算力对比的问题,以及和nvidiagpu算力的一些困惑,大家要是还不太明白的话,也没有关系,因为接下来将为大家分享,希望可以帮助到大家,解决大家的问题,下面就开始吧!3090与4080只对比渲染能力能效比功耗:3090TDP为350W,4...
大家好,感谢邀请,今天来为大家分享一下nvidia显卡算力对比的问题,以及和nvidia gpu算力的一些困惑,大家要是还不太明白的话,也没有关系,因为接下来将为大家分享,希望可以帮助到大家,解决大家的问题,下面就开始吧!
3090与4080只对比渲染能力
能效比功耗:3090 TDP为350W,4080为320W,后者性能更强且功耗更低,单位能耗渲染效率显著提升。总结4080优势:架构升级带来更高单精度算力、光追效率及DLSS 3支持,适合实时渲染和光追密集型任务。3090优势:大显存更适合超大规模3D场景或高分辨率纹理处理(如8K渲染)。选取建议:若追求渲染速度和新技术(如DLSS 3),选4080;若需显存容量应对极端负载,3090仍有一定价值。
综上所述,如果主要关注渲染能力,RTX 4080无疑是一个值得考虑的选取。它不仅在渲染效率上远超RTX 3090,还支持最新的技术特性,能够为用户提供更加高效、高质量的渲染体验。
ti:配备了24GB GDDR6X显存。4080 16g:则拥有16GB GDDR6X显存。在显存容量上,3090ti稍占优势,但对于大多数应用场景来说,16GB的显存也足够使用。
然而,实际测试结果揭示了不一样的情况。在3DMark测试中,4080 16g取得了289000分的成绩,远超3090ti的219000分。这一成绩主要反映了4080 16g在生产力和后期渲染、制作能力上的提升,相比3090ti提升了30%以上。在游戏性能方面,两款显卡的表现也各有千秋。

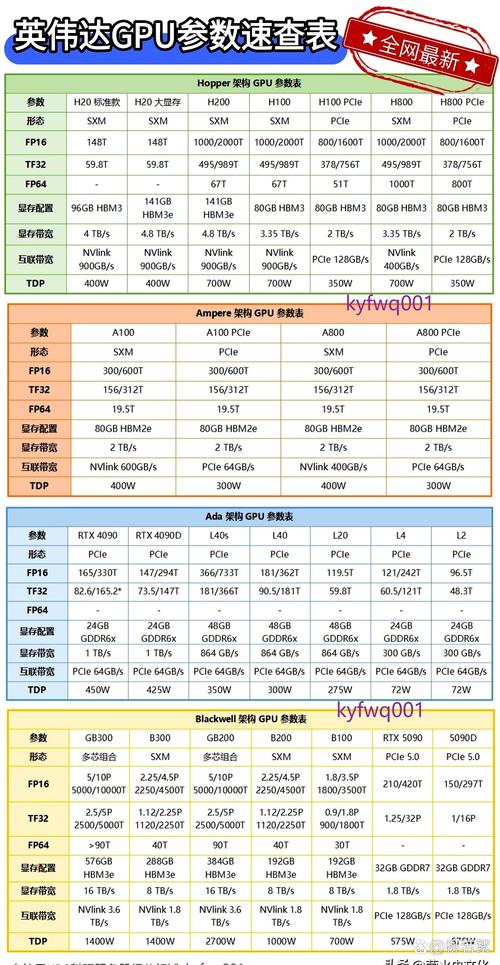
英伟达主流GPU参数速查表!(建议收藏)
以下是英伟达主流GPU(包括GB200和GB300系列)的参数速查表,帮助用户快速了解各型号GPU的关键参数。
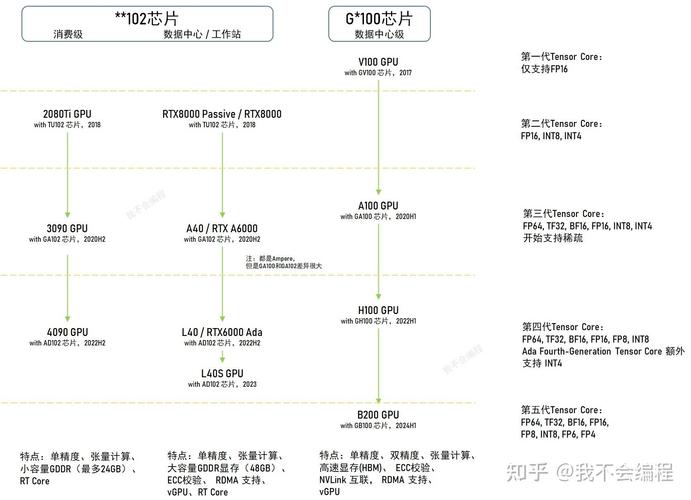
英伟达产品系列分类、架构、数据中心GPU所有型号及参数汇总(附国内外部分GPU对比)英伟达产品系列分类 GeForce系列(G系列)特点:主打消费级GPU,注重高性能图形处理和游戏特性,支持实时光线追踪和DLSS技术。应用领域:面向游戏玩家和普通用户。
Ada Lovelace:专为光线追踪和AI设计,推出高性能GPU如GeForce RTX 4080。Hopper:企业级应用GPU架构,如H100 NVL GPU,提供40Tb/s的I/O带宽和12倍的性能飞跃。
英伟达GPU主要分为数据中心级和消费级两大类。数据中心级GPU专为AI训练与推理优化,具备高算力密度、大容量显存和丰富的软件生态支持;消费级GPU则兼顾图形处理与计算能力,适用于混合计算与图形场景。
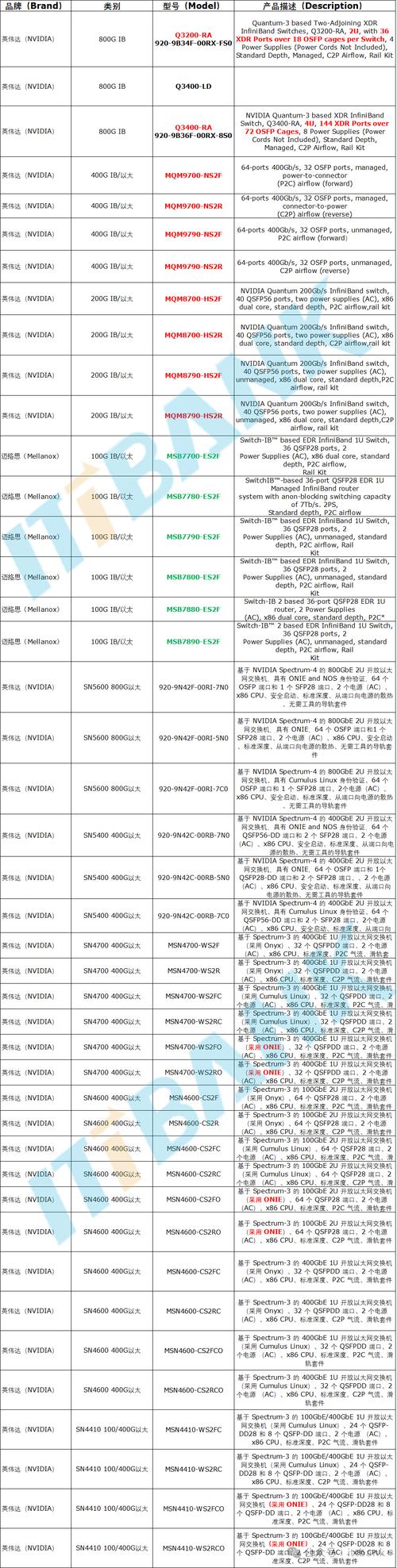
2024年GPU算力最新排名!
顶级算力GPU NVIDIA GeForce RTX 4080 SUPER 算力:823 TFLOPS 解析:凭借Ada Lovelace架构,这款GPU以惊人的算力位居榜首,成为近来市场上最强大的消费级GPU,适用于高端游戏、深度学习及科学计算等场景。
国产GPU排名前十(按2024年IDC销量数据及性能表现排序)分别为:华为升腾、百度昆仑芯、天数智芯、寒武纪、沐曦集成、燧原科技、摩尔线程、景嘉微、壁仞科技、砺算科技(东芯股份)。华为升腾以23%市场份额位居国产第一,升腾910D等芯片在AI训练领域表现突出,获行业广泛认可。
年截至8月的手机芯片排名前十如下:高通骁龙8至尊领先版:鲁大师跑分超128万,采用台积电3nm工艺,CPU主频47GHz,Adreno 830 GPU支持硬件光追,AI算力200 TOPS,是安卓阵营的顶尖芯片。
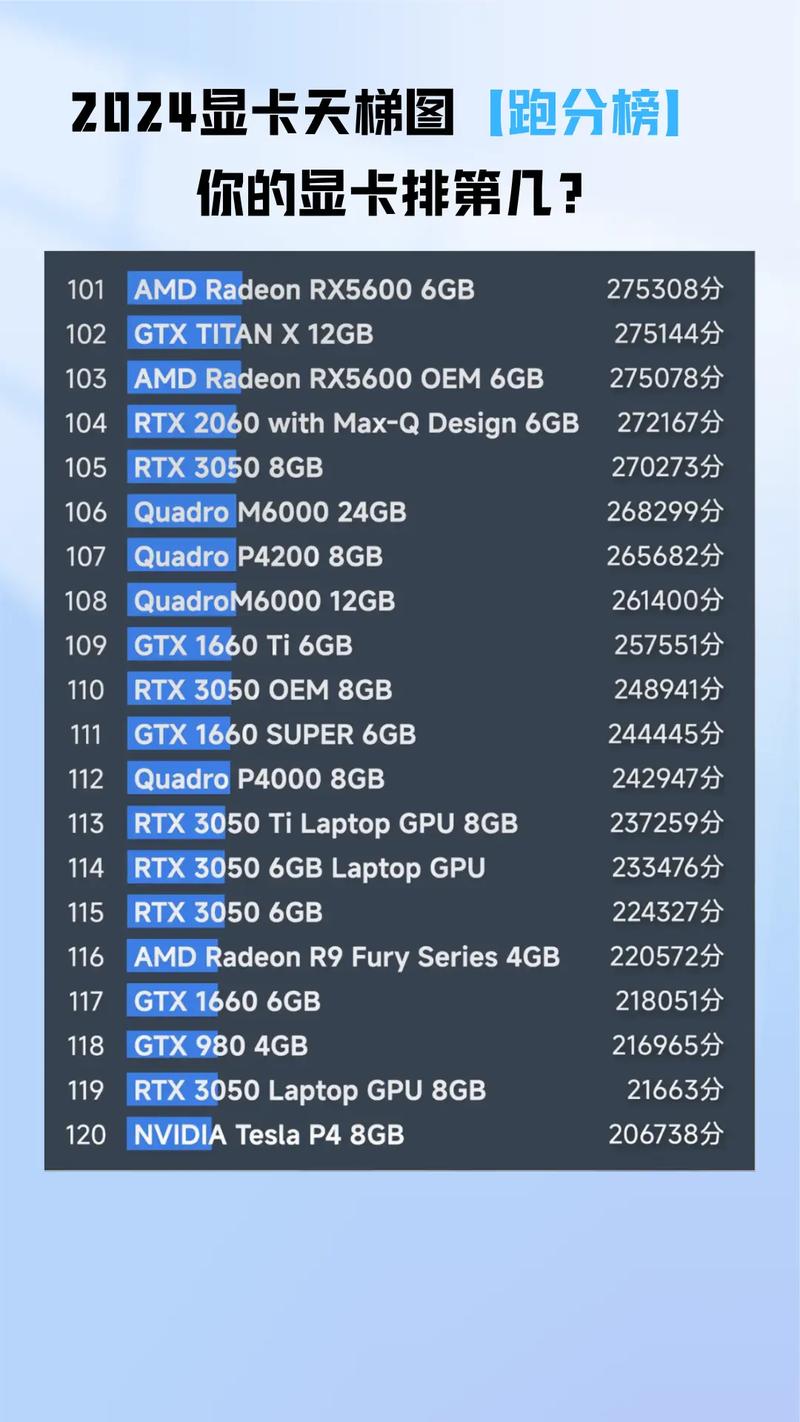
一文看懂英伟达系列显卡特点及性能参数对比
GeForce显卡是英伟达推出的主流消费级显卡,主要面向个人计算和游戏市场。它能够满足大多数游戏和一般图形处理的需求,如运行大型3D游戏、进行视频编辑、观看高清视频等。特点:高性价比,适合游戏玩家和对图形处理有一定要求的普通用户。
性能:FP32性能15 TFLOPS,FP64性能7 TFLOPS,Tensor性能626 TFLOPS。内存:显存容量提供40GB和80GB HBM2e两种版本,内存带宽高达2 TB/s(80GB版本)。功耗与接口:TDP 400W,支持PCIe 0。
典型型号性能对比:RTX 4090:拥有16384个CUDA核心,24GB GDDR6X显存容量,适合8K游戏和AI训练等高负载场景。RTX 3060 Ti:拥有4864个CUDA核心,8GB GDDR6显存容量,适合1080P高帧率游戏。专业图形卡:Quadro 系列(现整合为 RTX A 系列)定位:针对专业图形设计、影视渲染和工程建模领域。
英伟达各系列显卡在技术特性上也有所不同。RTX系列显卡支持实时光线追踪技术、DLSS超分辨率技术以及NVIDIA Reflex低延迟模式等先进技术。这些技术特性可以为用户带来更加逼真的游戏画面、更流畅的游戏体验以及更高效的生产力表现。
英伟达GPU型号详解及应用场景对比分析
〖One〗、英伟达GPU主要分为数据中心级和消费级两大类。数据中心级GPU专为AI训练与推理优化,具备高算力密度、大容量显存和丰富的软件生态支持;消费级GPU则兼顾图形处理与计算能力,适用于混合计算与图形场景。
〖Two〗、英伟达GPU卡A100、H100、A10和T4在架构、显存和使用场景上各有特色。
〖Three〗、应用场景:深度学习训练、推理、科学计算、大规模数据分析 A100是英伟达2020年发布的旗舰级数据中心GPU,基于Ampere架构,具有强大的计算能力和高带宽显存,适用于高性能计算(HPC)和深度学习任务。
〖Four〗、应用场景:主要面向建筑师、设计师、动画师等专业人士。L40/L40S 定位:数据中心级高性能计算GPU(加速卡)核心特性:L40/L40S专为数据中心设计,提供了极高的计算密度和能效比。它们支持多种并行计算框架,如CUDA、TensorRT等,能够加速深度学习、数据分析、科学计算等任务。
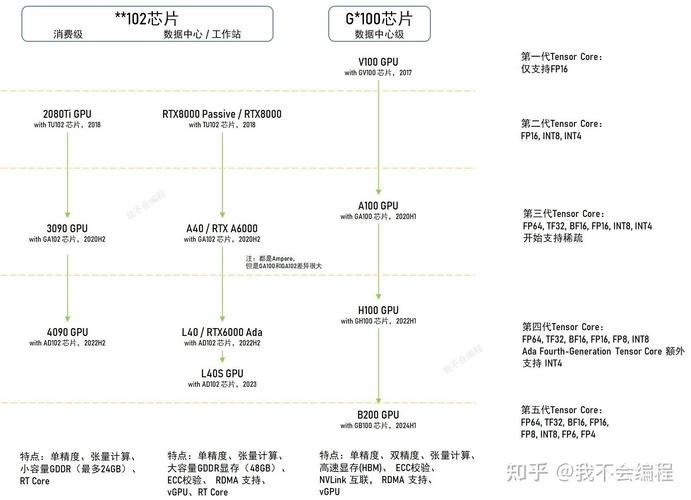
h20和5090算力
〖One〗、和H20显卡的主要区别体现在应用场景、技术前瞻性和算力性能等方面。应用场景 5090显卡:更适合高端游戏或内容创作。它在这些领域表现出色,能够提供流畅的游戏体验和高效的内容创作能力。然而,其AI训练能力相对较弱。H20显卡:更适合进行AI训练、超算模拟等高负载任务。
〖Two〗、H20和5090的算力对比因具体使用场景、配置和技术实现等因素而异,无法直接给出确定的算力高低判断。算力性能概述 H20芯片:在重返中国市场时,其算力性能在特定场景下得到了应用,并与国产芯片如华为升腾进行了对比测试。这些测试展示了H20在某些应用中的性能表现,但并未直接说明与5090之间的算力优劣。
〖Three〗、英伟达在中国推出的新品牌相关产品包括H20芯片、RTX PRO、RTX 5090 D V2。核心产品H20芯片:已解除禁令,虽不是性能最强的产品,但拥有出色的内存带宽,适用于大语言模型以及视觉、语言、动作模型的推理任务,是针对中国AI商用算力需求进行优化的产品。
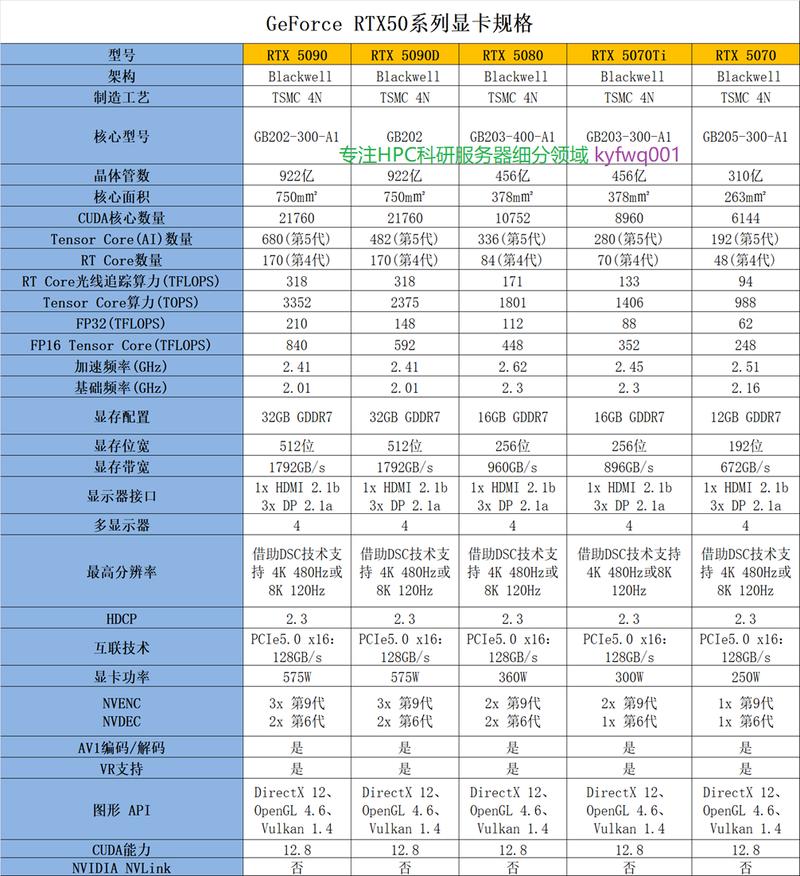
〖Four〗、RTX 5090的算力提升 在CES 2025上,英伟达CEO黄仁勋发布了全新的RTX Blackwell系列图形处理器,其中核心产品RTX 5090拥有920亿个晶体管、4000 AI TOPS(算力标识,尽管有说法表明其实际算力可能未完全释放)、380 RT TFLOPS和8 TB/s带宽。
2023年最新最全的显卡深度学习AI算法算力排名(包括单精度FP32和半精度F...
地表最强显卡H100 H100作为NVIDIA的最新一代旗舰显卡,在深度学习AI算法算力方面表现出色。其中,SXM版本的H100在半精度FP16上已经达到了近2000TFLOPS的惊人水平,远超其他显卡。然而,其售价也相对较高,达到了24万不含税的水平。
年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 NVIDIA H100:半精度FP16:近2000TFLOPS,表现极为出色,远超其他显卡。单精度FP32:虽然具体数值未提及,但通常半精度算力远高于单精度,H100的单精度性能同样非常强大。
年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 H100 SXM版本:在半精度FP16下展现出惊人实力,算力高达近2000TFLOPS,远超其他显卡。在单精度FP32下的算力虽然未具体提及,但预计也十分强劲。
年度显卡性能巅峰对决:FP32与FP16算力对比在深度学习的世界里,显卡性能无疑是决定计算效率的关键因素。本文将为您揭示2023年最新最全面的显卡算力排名,包括单精度FP32与半精度FP16的激烈较量,以及性价比的深度洞察。
年最新最全排名,涵盖单精度FP32和半精度FP16对比,为您深入了解显卡算力。专业计算卡信息来源:NVIDIA Professional Graphics Solutions | Linecard。地表最强显卡H100,性能惊人,SXM版本在半精度达到近2000TFLOPS,远超4090的162TFLOPS,费用优势也显著。
单精度算力gpu排名
在单精度(FP32)算力GPU排名中,表现突出的GPU型号包括英伟达H100、A100,AMD Instinct MI325X,以及国产的华为升腾910B等。英伟达H100:特点:具备高显存带宽和强大的计算能力。应用场景:适合高精度计算任务,如大型语言模型训练、科学计算、工程仿真等高性能需求场景。英伟达A100:特点:高性价比。
顶级算力GPU NVIDIA GeForce RTX 4080 SUPER 算力:823 TFLOPS 解析:凭借Ada Lovelace架构,这款GPU以惊人的算力位居榜首,成为近来市场上最强大的消费级GPU,适用于高端游戏、深度学习及科学计算等场景。
单精度FP32(未直接给出,但通常低于半精度)A100:半精度FP16:高算力表现 单精度FP32:同样具备出色的算力 其他高端显卡(如RTX 4090、Titan RTX等):这些显卡在单精度FP32和半精度FP16上均有不俗表现,但具体数值因型号和配置而异。
半精度FP16:近2000TFLOPS,表现极为出色,远超其他显卡。单精度FP32:虽然具体数值未提及,但通常半精度算力远高于单精度,H100的单精度性能同样非常强大。NVIDIA 4090:半精度FP16:162TFLOPS,与H100相比有显著差距。单精度FP32:具体数值未直接给出,但根据常识,其单精度性能应高于半精度。
如果你还想了解更多这方面的信息,记得收藏关注本站。




还没有评论,来说两句吧...