
nvidia显卡算力排名?nvidia显卡算力排名榜
本文摘要: 很多朋友对于nvidia显卡算力排行和nvidia显卡算力排行榜不太懂,今天就由小编来为大家分享,希望可以帮助到大家,下面一起来看看吧!2022年显卡算力天梯图高端显卡算力NvidiaCMP170HX:165MH/s作为Nvidia专为挖矿设计的显卡,CMP170HX在算力上表现出色...
很多朋友对于nvidia显卡算力排行和nvidia显卡算力排行榜不太懂,今天就由小编来为大家分享,希望可以帮助到大家,下面一起来看看吧!
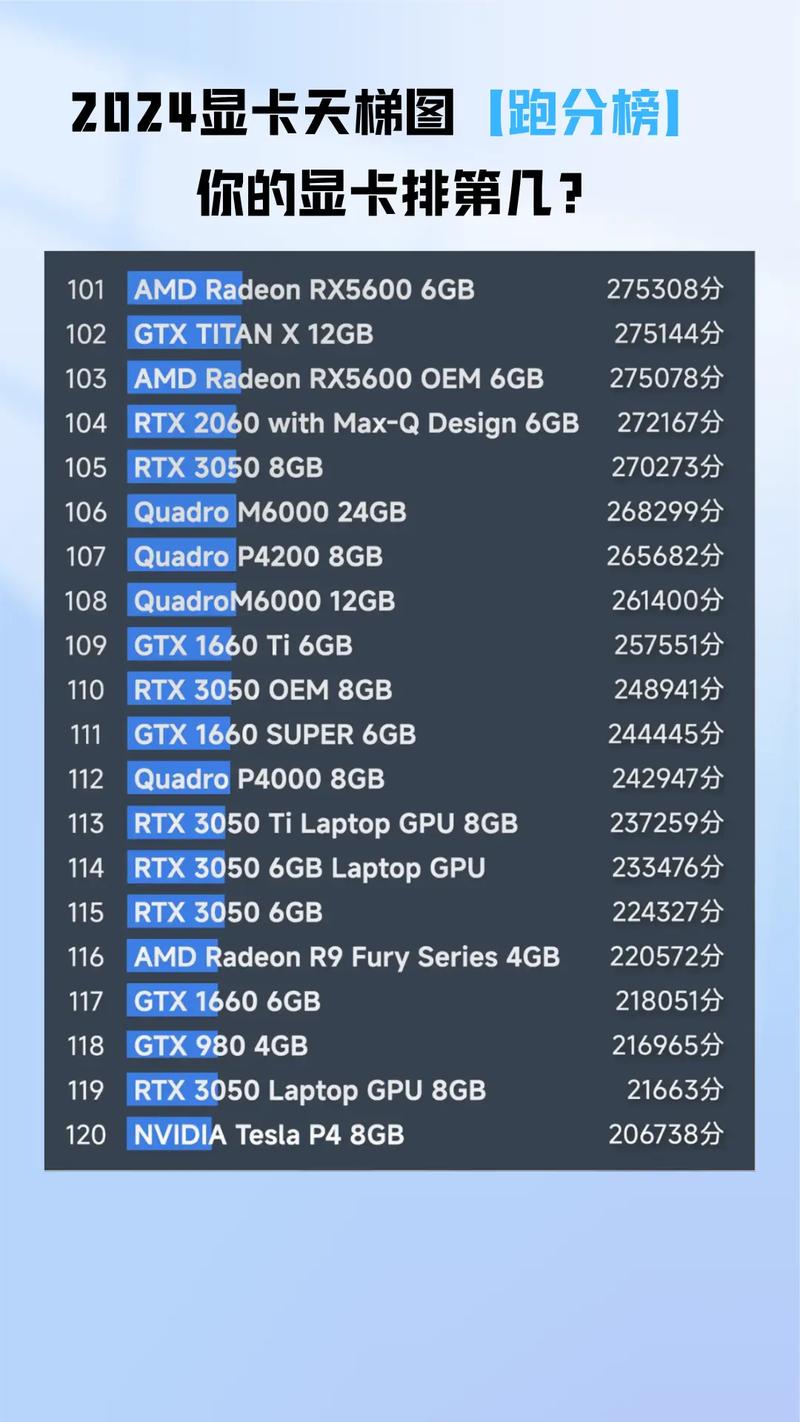
2022年显卡算力天梯图
高端显卡算力 Nvidia CMP 170HX:165 MH/s 作为Nvidia专为挖矿设计的显卡,CMP 170HX在算力上表现出色,适合大规模挖矿应用。Nvidia RTX 3090:1216 MH/s RTX 3090不仅是游戏玩家的梦想显卡,其强大的算力也使其成为挖矿领域的热门选取。
最后,显卡的算力也是衡量其性能的一个侧面,它能帮助您理解显卡在处理复杂图形任务时的效率。了解这些,将有助于您在购买时做出明智决策。
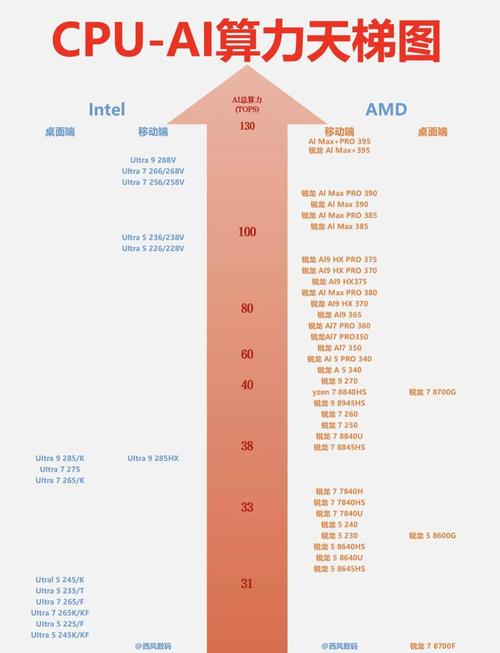
顶端显卡:天梯图顶端的是计算能力最强的显卡,它们通常拥有比较多的CUDA核心或流处理器,以及比较高的显存带宽和频率。这些显卡适合进行大规模的科学计算、深度学习、3D渲染等任务。性能阶梯:随着天梯图向下延伸,显卡的计算能力逐渐降低。
单精度算力天梯图 传统AI模型训练:主要依赖于单精度算力,因为它提供了足够的精度,特别是在梯度计算和参数更新时,能够保持数值稳定性。颜色区分:图中深绿色表示四零系显卡,浅绿色表示三零系显卡,更浅的绿色表示二零系显卡。
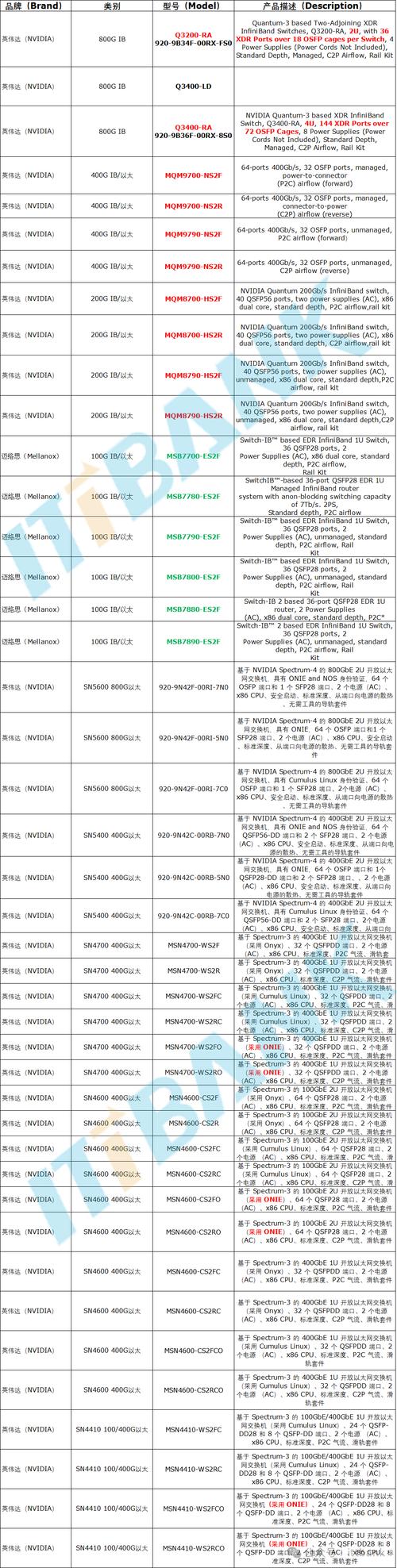
NVIDIA和AMD各型号显卡ETH算力功率一览表最新版
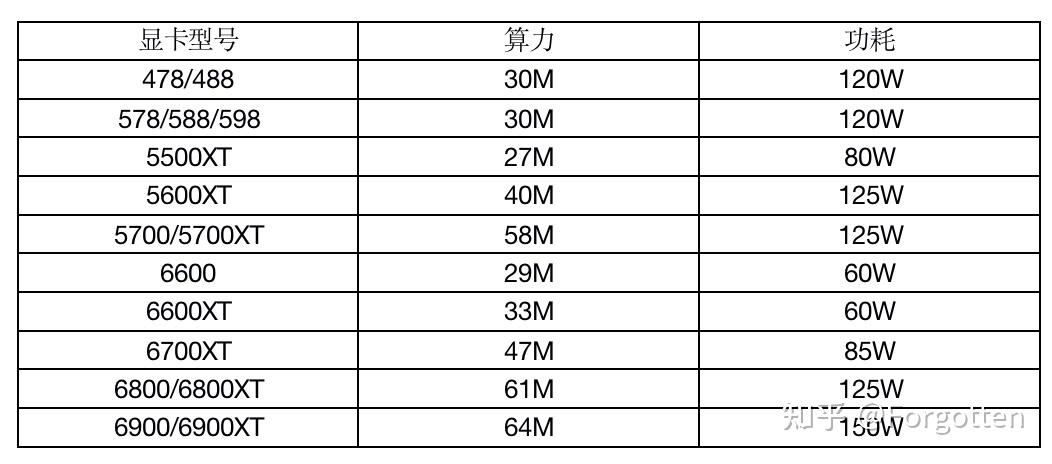
〖One〗、AMD显卡: 400系列: 478/488/578系列:部分型号支持ETH挖矿,但算力与功耗表现各异。 500系列: 588/598系列:在ETH挖矿中表现突出,算力与功耗平衡较好。 5500XT/5600XT/5700XT:中高端型号,算力强劲,功耗适中。 600系列: 6600系列:具有不错的算力与功耗表现,适合挖矿。
〖Two〗、NVIDIA显卡的ETH算力和功耗如下:大部分支持的6GB以上显存型号包括1060/1060Ti/1070系列、1080系列、1660/1660Ti/1660Super等,以及20系列、30系列的部分型号,如2060/2080Ti/3060LHR等,这些都是近来还能参与挖矿的选项。需要注意的是,部分有锁版本的显卡在NBMiner v36的解锁下,算力有所不同。
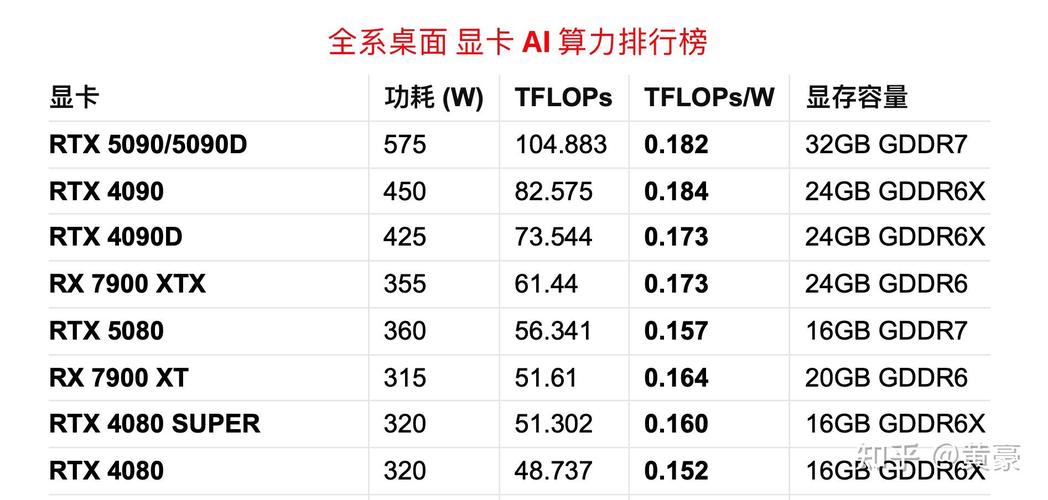
〖Three〗、NVIDIA GeForce RTX 4070 Ti SUPER 算力:804 TFLOPS 解析:作为NVIDIA的另一款高端显卡,其算力紧随RTX 4080 SUPER之后,同样展现了NVIDIA在高端市场的强大统治力。
显卡AI算力排名
单精度算力天梯图 传统AI模型训练:主要依赖于单精度算力,因为它提供了足够的精度,特别是在梯度计算和参数更新时,能够保持数值稳定性。颜色区分:图中深绿色表示四零系显卡,浅绿色表示三零系显卡,更浅的绿色表示二零系显卡。
A100:专为数据中心和AI应用设计,提供高算力、低延迟和高效能。H100:作为NVIDIA的最新一代专业计算卡,H100在算力、能效和内存带宽等方面均实现了显著提升。2023地表最强显卡H100 H100作为NVIDIA的最新一代旗舰显卡,在深度学习AI算法算力方面表现出色。
单精度算力:RTX5090的单精度算力比上代强约27%,在消费级显卡中模型训练效率比较高。FP4算力:在新的基准下,RTX50系列显卡的排位大幅度上涨,显示出其在AI性能方面的显著提升。显存容量:RTX5090拥有近来消费级显卡中最大的显存容量,对于AI训练来说具有绝对优势。
A卡:在高负载场景下爆显存,不建议用于跑AI。SDXL性能排名 在SDXL的测试环境中,显存成为决定性能的关键因素。测试方式为1600*1024分辨率,无LoRA、无Controlnet、无高清修复,直出。
年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 NVIDIA H100:半精度FP16:近2000TFLOPS,表现极为出色,远超其他显卡。单精度FP32:虽然具体数值未提及,但通常半精度算力远高于单精度,H100的单精度性能同样非常强大。
年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 H100 SXM版本:在半精度FP16下展现出惊人实力,算力高达近2000TFLOPS,远超其他显卡。在单精度FP32下的算力虽然未具体提及,但预计也十分强劲。
2023年最新最全的显卡深度学习AI算法算力排名(包括单精度FP32和半精度F...
〖One〗、地表最强显卡H100 H100作为NVIDIA的最新一代旗舰显卡,在深度学习AI算法算力方面表现出色。其中,SXM版本的H100在半精度FP16上已经达到了近2000TFLOPS的惊人水平,远超其他显卡。然而,其售价也相对较高,达到了24万不含税的水平。
〖Two〗、年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 NVIDIA H100:半精度FP16:近2000TFLOPS,表现极为出色,远超其他显卡。单精度FP32:虽然具体数值未提及,但通常半精度算力远高于单精度,H100的单精度性能同样非常强大。
〖Three〗、年最新最全的显卡深度学习AI算法算力排名如下:单精度FP32与半精度FP16算力对比 H100 SXM版本:在半精度FP16下展现出惊人实力,算力高达近2000TFLOPS,远超其他显卡。在单精度FP32下的算力虽然未具体提及,但预计也十分强劲。
〖Four〗、年度显卡性能巅峰对决:FP32与FP16算力对比在深度学习的世界里,显卡性能无疑是决定计算效率的关键因素。本文将为您揭示2023年最新最全面的显卡算力排名,包括单精度FP32与半精度FP16的激烈较量,以及性价比的深度洞察。
〖Five〗、年最新最全排名,涵盖单精度FP32和半精度FP16对比,为您深入了解显卡算力。专业计算卡信息来源:NVIDIA Professional Graphics Solutions | Linecard。地表最强显卡H100,性能惊人,SXM版本在半精度达到近2000TFLOPS,远超4090的162TFLOPS,费用优势也显著。
〖Six〗、半精度算力天梯图 混合精度算力:现在很多AI模型支持用混合精度算力(FP16 + FP32),使用半精度进行大部分计算,使用单精度进行关键的参数更新,效率更高。张量核心优化:英伟达的张量核心对半精度算力有显著优化,用于加速矩阵乘法和累加运算,提升计算性能。
2024年GPU算力最新排名!
顶级算力GPU NVIDIA GeForce RTX 4080 SUPER 算力:823 TFLOPS 解析:凭借Ada Lovelace架构,这款GPU以惊人的算力位居榜首,成为近来市场上最强大的消费级GPU,适用于高端游戏、深度学习及科学计算等场景。
年截至8月的手机芯片排名前十如下:高通骁龙8至尊领先版:鲁大师跑分超128万,采用台积电3nm工艺,CPU主频47GHz,Adreno 830 GPU支持硬件光追,AI算力200 TOPS,是安卓阵营的顶尖芯片。
在单精度(FP32)算力GPU排名中,表现突出的GPU型号包括英伟达H100、A100,AMD Instinct MI325X,以及国产的华为升腾910B等。英伟达H100:特点:具备高显存带宽和强大的计算能力。应用场景:适合高精度计算任务,如大型语言模型训练、科学计算、工程仿真等高性能需求场景。英伟达A100:特点:高性价比。
好了,文章到此结束,希望可以帮助到大家。




还没有评论,来说两句吧...